

Ability
Startup
Tips
Workstyle
中国のAIスタートアップ、DeepSeekが新しいAIモデル「DeepSeek R1」をリリースし、AI業界に衝撃を与えました。
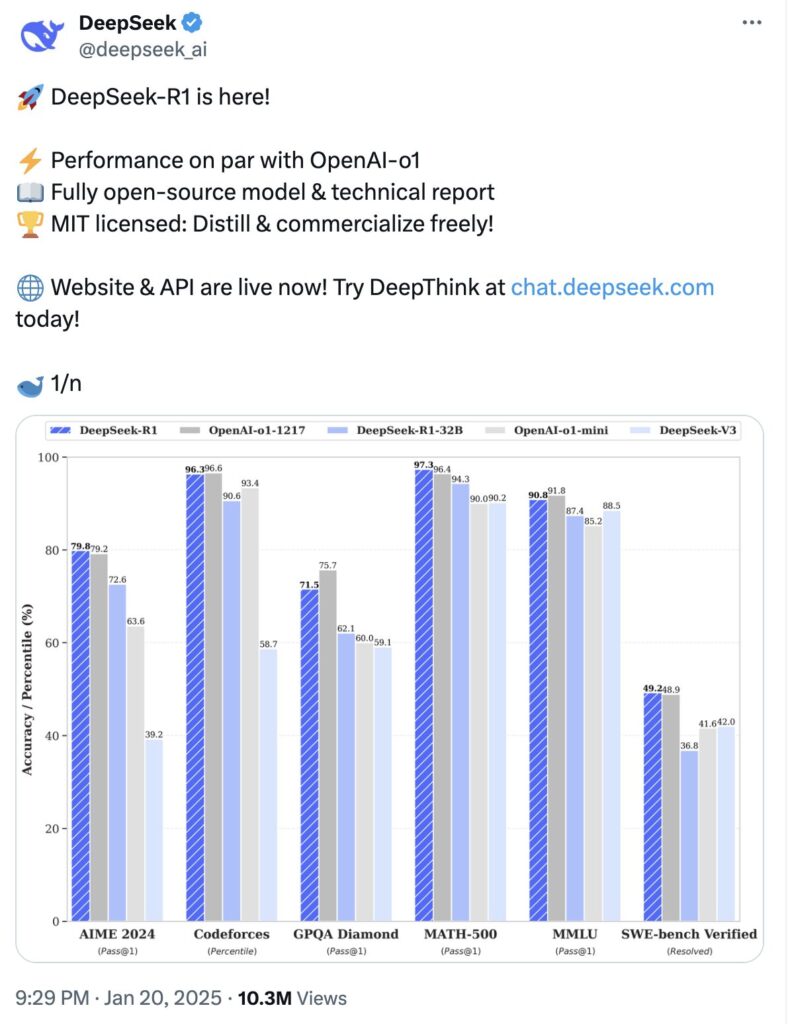
DeepSeek R1は、OpenAIのChatGPT o1と同等の性能を持つとされ、開発コストが大幅に低いことが話題になり、Nvidiaの株価が急落し、市場から6000億ドル近くの価値が失われたと言われています。
このDeepSeekについては、今後のAI開発における重要な分岐点になりそうなので、現時点での情報をまとめてみたいと思います。
2024年12月に発表された「DeepSeek V3」は、わずか2か月という短期間で、開発費用558万ドルという低コストながら、6710億パラメータを持つ大規模言語モデルとしてOpenAIやMetaのモデルと肩を並べる性能を実証して、インパクトを与えていました。
兼ねてよりDeepSeekは商用アプリケーションではなく基礎技術の構築に注力していて、すべてのモデルをオープンソース化することを公言していました。実際に2024年5月にはDeepSeek V2というオープンソースモデルをリリースしており、そのパフォーマンスは話題になっていたようです。
そして2025年1月20日にDeepSeek-R1を公開し、世界に衝撃を与えました。
DeepSeek-R1(Github)
商用利用も可能なMITライセンスで、Github上にソースコードを公開したことは一番のインパクトでした。オープンソースであれば多くのエンジニアが検証に関わることができますし、改修が可能です。
実際にサイバーエージェントがDeepSeekのソースコードを複製して、日本語データで追加学習を行ったLLMを公開していました。
cyberagent/DeepSeek-R1-Distill-Qwen-32B-Japanese
AIモデルはOpenAIやAnthropicなどが、多額の投資を行いながら開発競争を行ない、AIモデルを基盤にビジネス展開していました。それを同等程度のものをオープンソース化、つまり無料で複製可能になるとOpenAIやAnthropicにとっては今後の事業価値が下がる可能性があります。
また多くのAI開発はOpenAIやAnthropicなどが作るAIモデルをベースに、アプリケーションレイヤーを開発してきた多くのスタートアップにとって、DeepSeekのオープンソースのAIモデルからの登場は、よりサービスコストを下げて、独自のリッチな体験やサービスを提供できる可能性が広がります。
DeepSeek V3は、わずか558万ドル(約8億円)の予算と2か月という短期間で開発され、従来のモデル開発コストの10分の1以下を実現したと言われています。
もしアナウンス通りだとすると、5000億ドル(約77兆円)を投資するOpen AIのスターゲイトプロジェクトの発表と比較すると、いかにコンパクトなコストで開発したかが分かります。必要なGPU数も従来のモデル(例: ChatGPT)に比べて約5分の1で済み、効率的な学習アルゴリズムが採用されています。
またOpenAIの従業員数は約4,500人と言われていますが、DeepSeek は、200人未満の小規模なチームでOpen AIと同等のものを構築した、というのもGIANT KILLINGの印象です。
Anthropic、Google,、OpenAIなどの大規模言語モデル(LLMs)では Post-training(大規模言語モデルの事前学習後に行う追加学習)が重要視され、推論精度・社会的価値観との整合・ユーザ嗜好への最適化が行われていました。
一方、DeepSeekは「DeepSeek-V3-Base」というアーキテクチャーをベースに、強化学習(RL) ステップを積み重ねることでOpenAI-o1に匹敵する性能に到達しました。
つまりインセンティブを最大化することを目指し、少量のCoT(Chain of Thought)という思考のステップ分解を促すデータセットをAIに与え、その後はAI自身で推論プロセスを行わせました。そうするとインセンティブ設計だけで自然に「自己検証」や「反省的思考」などのような高度な推論が、勝手に現れたということです。
重要なのは、教師データが重要と思われていましたが、AIが自分で推論した方が効率的で高度な能力を獲得できたという点です。
強化学習はDeepMindによるAlphaGoが、囲碁チャンピオンを破ったあとで、AlphaGo Zeroという人間の教師データを一切使わないモデルを開発したところ、AlphaGo ZeroがAlphaGoに圧勝をしたという話がありますが、人間が提供するデータはAIにとってはノイズなのかもしれません。

1/27には、DeepSeekがApp Store(アメリカ国内) で1位になりました。
Nvidia株($NVDA)には、DeepSeek の衝撃で17% 下落して取引を終了し、時価総額が 5,900 億ドル減少しました。その他にもハイテク株は軒並み下落しました。
日本においても半導体関連株に影響を与えました。
DeepSeekショックで日経平均大幅安 投資評価修正迫る
DeepSeek R1の公開直後から、世界中のエンジニアがこのオープンソースのソースコードの検証を行なっています。
結果としてはかなり良い感触のようです。
DeepSeek-R1とOpenAI o1の比較で、多くの場面で同等程度の確認がされており実用的であるようです。
中には分散型 DeepSeek-R1 をデプロイして、dapps内でDeepSeek-R1を呼び出せるようにしている例もありました。
ちなみに現在、多くの人がテストしているDeepSeek R1の蒸留版(Distilled Models)は、元の巨大モデルであるDeepSeek R1(671Bパラメータ)の知識を小型モデルに凝縮した軽量バージョンです。
実際に完全なハードウェアとソフトウェアでセットアップしようとすると、コストは 6,000 ドルかかるようです。

DeepSeekのユニークな戦略を見ると、DeepSeekの創業者、梁文峰(Liang Wenfeng)に興味がいきます。彼は量化投資(クオンツ運用)の分野でAIと数学を駆使し、High-Flyer (幻方) というわずか数年で運用資産80億ドル規模にまで成長させたヘッジファンドを持っています。
Deepseek は High-Flyer から全額出資されており、外部からの資金調達の予定はないということです。つまりこのプロジェクトは完全に潤沢な資金を使って、基盤技術の研究を重視した開発を行なっています。Deepseek のミッションステートメントは「好奇心を持ってAGIの謎を解明する」。そのゴールはAGIの構築であり、マネタイズすることは目的ではない、という部分は他の企業と異なるスタンスです。
梁文峰の人物像についてChina Talkのライターはこのように述べています。
褒めすぎじゃないかと思いますが、それぐらいカリスマ性があるということなのでしょう。
Deepseek R1をオープンソースとして公開することで、その成果を広めて、AIエコシステム全体のレベルを底上げするというアプローチは、スケールするためにクローズドに進んだOpen AIとは真逆のスタンスでその対比が今回のインパクトにもつながっていると感じます。
梁文峰へのインタビュー記事から印象的だった点を挙げてみます。
言葉一つ一つがビジョナリーで、思想家としての側面を窺える言葉だと思いました。そして中国に対する思いと、イノベーションとAGI構築のための強い思いが伝わってきます。
イノベーションを生み出すための組織作りやカルチャーの考え方も興味深いものがありました。
イノベーションに本当に役立つのは経験ではなく、本当に頭が良くてハングリー精神だということを、よく理解し、そのような環境を作っているのは素晴らしいと思いました。
次世代の大型モデルの研究に集中する梁文峰は、あくまでAGI構築に全エネルギーを集中させています。
彼の思想はPerplexity AIのCEO、アラヴィンド・スリニヴァスが目指す「ゼロから知識体系を構築するAI」や、先も事例で挙げたAlphaZeroの「人間を模倣せずにゼロから学習する」思想と似ていて印象的でした。
DeepSeekについては中国政府も関心を持っていてがっつりつながっていると考えた方が良さそうです。DeepSeekのプライバシーポリシーは、データが中国国内のサーバーに保存される仕様ということなので、中国政府が法的要件に基づいてアクセス可能な状態です。つまりAPIでの接続については「機密情報や個人情報のデータ」については、中国政府のコントロール下にあるというのは考慮しておくべきだと思います。
天安門事件などの特定の歴史的、政治的トピックについては回答を避けたり、偏った情報を提供するリスクがあります。
しかしオープンソースの方は今後も検証が進み、より適正化されていくことが期待されます。
Deepseek R1 の登場は、この数年の中で印象的なブレークスルーの1つです。
オープンソースの流れはどこかで来ると思っていたけど、こんなに早く来るのかというのが個人的な印象です。5-10年後だと思っていた未来が予想を超えるスピードで進化していく瞬間に立ち会えているのはラッキーです。1年で10xどころか100xとか1000xで変化するテクノロジーですが、本当にいろんな可能性の選択肢が増えていくので、ワクワクしますね。
AIに関しては戦い方が変わったということだし、アメリカの強力なプラットフォーマーだけの戦いではなくなったということだと思います。一方でかなり競争力が必要になるので、戦略が重要になります。
Hugging Face へ出資しているSalesforceのMarc Benioffは「AI の真の価値はデータとメタデータだ」と述べ、モデル開発競争からデータ価値に市場が移ることを示唆しています。
ある噂によると、Deepseek はOpne AIのOperatorよりも優れたAIエージェントのバージョンを持っており、リリース予定があり、しかも無料になるということです。このようにハードウェアとソフトウェアの方々でAIが開発競争をより激化させており、どの企業も「セーフティーゾーン」はなく、イノベーションの速度はより加速していきます。
アメリカによる中国への経済制裁により、Nvidia H100など高度なAIチップを手に入れられなかったDeepSeekは、アルゴリズムと強化学習を屈指して、より効率的な方法を生み出すきっかけとなり今回の技術革新につながりました。
今回のDeepSeekのインパクトにおける重要な点は、AIモデルのオープンソースの可能性を示したことで、より多くの未来のイノベーションの幅とスピードが拡張したことです。強化学習をハックすることで、スケーリングするという道筋を示したことにより、いろんな研究機関や企業でこの手法を参考にして、次々と新たなLLMモデルがオープンソースで公開されていくことになります。
2025年中にも、DeepSeekで得られた知見を参照し、技術革新のギアがさらに上がることが想定されるので、日々マーケットと技術の現在地を注視しながら、未来を見極めていく必要があると思います。
DeepSeek-R1についての論文
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
数学的推論についての論文
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseek: The Quiet Giant Leading China’s AI Race
Two interviews with the founder of DeepSeek
※本記事では一部でClaude、ChatGPT、Midjourney、DALL-E3などの生成AIを活用して作成しています。



